

들어가며
본 포스팅은 <파이썬 알고리즘 인터뷰> 책에서 다룬 리트코드 문제들을 다루고 있습니다.
문제들은 모두 리트코드에서 출제된 문제들이며, 문제 풀이의 많은 부분을 책의 힌트와 해설을 참고하였습니다.
포스팅되는 모든 문제들의 목록과 풀이는 파이썬 알고리즘 인터뷰에서 제공하는 깃허브에서 확인하실 수 있습니다.
문제
Given a string s, find the length of the longest substring without repeating characters.
중복 문자가 없는 가장 긴 부분 문자열의 길이를 리턴하라
입출력 예시
Example 1:
Input: s = "abcabcbb"
Output: 3
Explanation: The answer is "abc", with the length of 3.
Example 2:
Input: s = "bbbbb"
Output: 1
Explanation: The answer is "b", with the length of 1.
Example 3:
Input: s = "pwwkew"
Output: 3
Explanation: The answer is "wke", with the length of 3.
Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.
생각과정
투포인터를 쓰면 해결될거라고 생각했고, 이런 식으로 하면 되겠다 싶었는데 구현에 실패했다.
left 포인터를 i로 설정하고 right 포인터를 1개씩 늘려나가면서 중복된 문자가 나오면 해당 문자열을 테이블에 넣고 다음 for문으로 넘어가게끔 구현하고 싶었는데 어디서 잘못된 건지 모르겠다.
뭔가 풀릴 듯 하면서도 계속 틀려서 고집부리다가 시간을 너무 많이 썼다. 바로 풀이해보자.
풀이

풀이의 접근 방식이다. 중복된 문자가 나타나기 직전까지의 문장의 길이를 저장하고 다음 start 포인터로 이동하는 투포인터와 슬라이딩 윈도우 방식이다. 뭔가 내가 생각한거랑 다르지 않은데... 우선 코드를 보자
def lengthOfLongestSubstring(s: str) -> int:
# 새로운 해시 테이블 생성
used = {}
# 시작 포인터와 문자열의 최대 길이 설정
max_length = start = 0
for index, char in enumerate(s):
# 뽑아온 문자가 테이블에 존재한다면 중복된 문자가 나타난 것이므로 start 포인터를 옮겨준다.
if char in used:
start = used[char] + 1
# 뽑아온 문자가 테이블에 존재하지 않는다면, 지금까지 나왔던 가장 긴 문자열의 길이와
# 현재의 문자열 길이 중 큰 값으로 업데이트 해준다.
# 여기서 index - start + 1은 현재 인덱스에서 지금까지 옮겨온 start의 길이를 빼고,
# 인덱스보다 길이가 1이 더 크므로 +1을 해준다.
else:
max_length = max(max_length, index - start + 1)
# 현재 문자를 키로 하는 테이블에 현재 위치를 넣어준다. 이건 start 포인터를 움직이기 위해 사용한다.
used[char] = index
return max_length우선 해시테이블을 생성해준다.
이 코드에서는 투 포인터의 left와 right를 max_length와 start로 지정해주었다. 투 포인터의 오른쪽 포인터를 이용해서 중복이 없는 가장 긴 문자열의 길이를 구하겠다는 의도임을 알 수 있다.
입력은 풀이에 나와있는 abcabcbb로 하기로 하고, 코드를 인간의 생각 흐름대로 쫓아가보자.
첫 시작은 포인터 0부터 시작한다. 가장 첫번째 문자인 a가 가장먼저 나오는 중복이 없는 문자열이므로 테이블에 넣어준다.
이때 max_length의 길이는 max_length와 index - start + 1 중 더 큰 값이 들어가게 되는데, 이 공식에 대한 이해는 조금 뒤에서 이해해보자.
max_length를 구해줬다면 현재 돌고있는 문자를 key로 하는 테이블 요소에 현재 위치를 넣어준다. 현재 위치를 넣어주는 이유는 후에 중복 문자가 나왔을 때, start 포인터를 옮겨주는 데에 사용하기 위해서이다.
여기서 해시 테이블의 쓸모가 무엇인지 알 수 있다.
중복 문자를 판단할 때, 배열을 사용하게 된다면 현재 도는 for문에 추가로 배열에서 문자가 있는지 검색하는 과정이 추가가 된다. 그렇게 되면 수행 속도가 해시 테이블을 사용할 때보다 훨씬 느려지게 되기 때문에, key를 가지고 중복문자가 있는 지 확인할 수 있는 해시 테이블을 사용하는 것이다.
for문이 몇번 돌아가면서 used에는 a와 b, 그리고 c가 들어가게 된다. 다시 a가 등장했을 때 코드는 if문을 타게 되는데, 그때 start의 값이 옮겨진다.
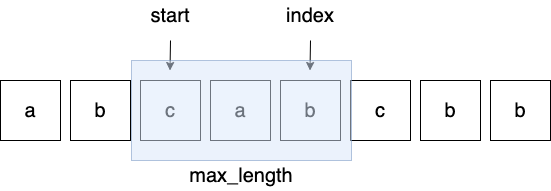
이제 index - start + 1에 대해 이해해보자
위 그림은 for문이 몇번 진행되어 이미 abc와 bca까지 리턴되고 나서 start 포인터가 인덱스 2까지 옮겨갔을 때의 그림이다.
그림으로 보면 왜 저렇게 최대 길이를 구하는 지 알 수 있다. index에 start를 빼주면 2라는 값이 나오는데, 인덱스는 길이보다 1이 작기 때문에 1을 더해 max_length를 만들 수 있다.
for문이 완전히 돌고나면 max_length는 문제에서 요구하는 중복 문자 없는 가장 긴 문자열이 된다.
마치며
해시 테이블을 제대로 이해하고 응요하는 능력, 투포인터와 슬라이딩에 대한 이해가 많이 부족했던 것 같다.
해시 테이블의 장점은 배열은 선형검색을 해야하는 데에 반해 시간복잡도 O(1)만에 원하는 값을 찾아낼 수 있는 것인데 사용방법을 잘 몰라서 습관처럼 배열로 풀어내려고 기를 쓰다보니 제대로 된 답이 도출되지 않은 것 같다.
음. 오늘 나온 개념에 대해 조금 쉬운 문제를 풀어봐야겠다.
'Algorithm > Leetcode' 카테고리의 다른 글
| [leetcode] 200. 섬의 개수 (Number of Islands) (0) | 2022.05.20 |
|---|---|
| [leetcode] 706. 해시맵 디자인 (Design HashMap) (0) | 2022.05.19 |
| [leetcode] 29. 보석과 돌 (Jewels-and-stones) (0) | 2022.05.18 |
| [leetcode] 25. 원형 큐 디자인 (Design Circular Queue) (0) | 2022.05.17 |
| [leetcode] 739. 일일 온도 (Daily Temperatures) (0) | 2022.05.17 |
들어가며
본 포스팅은 <파이썬 알고리즘 인터뷰> 책에서 다룬 리트코드 문제들을 다루고 있습니다.
문제들은 모두 리트코드에서 출제된 문제들이며, 문제 풀이의 많은 부분을 책의 힌트와 해설을 참고하였습니다.
포스팅되는 모든 문제들의 목록과 풀이는 파이썬 알고리즘 인터뷰에서 제공하는 깃허브에서 확인하실 수 있습니다.
문제
Given a string s, find the length of the longest substring without repeating characters.
중복 문자가 없는 가장 긴 부분 문자열의 길이를 리턴하라
입출력 예시
Example 1:
Input: s = "abcabcbb"
Output: 3
Explanation: The answer is "abc", with the length of 3.
Example 2:
Input: s = "bbbbb"
Output: 1
Explanation: The answer is "b", with the length of 1.
Example 3:
Input: s = "pwwkew"
Output: 3
Explanation: The answer is "wke", with the length of 3.
Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.
생각과정
투포인터를 쓰면 해결될거라고 생각했고, 이런 식으로 하면 되겠다 싶었는데 구현에 실패했다.
left 포인터를 i로 설정하고 right 포인터를 1개씩 늘려나가면서 중복된 문자가 나오면 해당 문자열을 테이블에 넣고 다음 for문으로 넘어가게끔 구현하고 싶었는데 어디서 잘못된 건지 모르겠다.
뭔가 풀릴 듯 하면서도 계속 틀려서 고집부리다가 시간을 너무 많이 썼다. 바로 풀이해보자.
풀이
풀이의 접근 방식이다. 중복된 문자가 나타나기 직전까지의 문장의 길이를 저장하고 다음 start 포인터로 이동하는 투포인터와 슬라이딩 윈도우 방식이다. 뭔가 내가 생각한거랑 다르지 않은데... 우선 코드를 보자
def lengthOfLongestSubstring(s: str) -> int:
# 새로운 해시 테이블 생성
used = {}
# 시작 포인터와 문자열의 최대 길이 설정
max_length = start = 0
for index, char in enumerate(s):
# 뽑아온 문자가 테이블에 존재한다면 중복된 문자가 나타난 것이므로 start 포인터를 옮겨준다.
if char in used:
start = used[char] + 1
# 뽑아온 문자가 테이블에 존재하지 않는다면, 지금까지 나왔던 가장 긴 문자열의 길이와
# 현재의 문자열 길이 중 큰 값으로 업데이트 해준다.
# 여기서 index - start + 1은 현재 인덱스에서 지금까지 옮겨온 start의 길이를 빼고,
# 인덱스보다 길이가 1이 더 크므로 +1을 해준다.
else:
max_length = max(max_length, index - start + 1)
# 현재 문자를 키로 하는 테이블에 현재 위치를 넣어준다. 이건 start 포인터를 움직이기 위해 사용한다.
used[char] = index
return max_length우선 해시테이블을 생성해준다.
이 코드에서는 투 포인터의 left와 right를 max_length와 start로 지정해주었다. 투 포인터의 오른쪽 포인터를 이용해서 중복이 없는 가장 긴 문자열의 길이를 구하겠다는 의도임을 알 수 있다.
입력은 풀이에 나와있는 abcabcbb로 하기로 하고, 코드를 인간의 생각 흐름대로 쫓아가보자.
첫 시작은 포인터 0부터 시작한다. 가장 첫번째 문자인 a가 가장먼저 나오는 중복이 없는 문자열이므로 테이블에 넣어준다.
이때 max_length의 길이는 max_length와 index - start + 1 중 더 큰 값이 들어가게 되는데, 이 공식에 대한 이해는 조금 뒤에서 이해해보자.
max_length를 구해줬다면 현재 돌고있는 문자를 key로 하는 테이블 요소에 현재 위치를 넣어준다. 현재 위치를 넣어주는 이유는 후에 중복 문자가 나왔을 때, start 포인터를 옮겨주는 데에 사용하기 위해서이다.
여기서 해시 테이블의 쓸모가 무엇인지 알 수 있다.
중복 문자를 판단할 때, 배열을 사용하게 된다면 현재 도는 for문에 추가로 배열에서 문자가 있는지 검색하는 과정이 추가가 된다. 그렇게 되면 수행 속도가 해시 테이블을 사용할 때보다 훨씬 느려지게 되기 때문에, key를 가지고 중복문자가 있는 지 확인할 수 있는 해시 테이블을 사용하는 것이다.
for문이 몇번 돌아가면서 used에는 a와 b, 그리고 c가 들어가게 된다. 다시 a가 등장했을 때 코드는 if문을 타게 되는데, 그때 start의 값이 옮겨진다.
이제 index - start + 1에 대해 이해해보자
위 그림은 for문이 몇번 진행되어 이미 abc와 bca까지 리턴되고 나서 start 포인터가 인덱스 2까지 옮겨갔을 때의 그림이다.
그림으로 보면 왜 저렇게 최대 길이를 구하는 지 알 수 있다. index에 start를 빼주면 2라는 값이 나오는데, 인덱스는 길이보다 1이 작기 때문에 1을 더해 max_length를 만들 수 있다.
for문이 완전히 돌고나면 max_length는 문제에서 요구하는 중복 문자 없는 가장 긴 문자열이 된다.
마치며
해시 테이블을 제대로 이해하고 응요하는 능력, 투포인터와 슬라이딩에 대한 이해가 많이 부족했던 것 같다.
해시 테이블의 장점은 배열은 선형검색을 해야하는 데에 반해 시간복잡도 O(1)만에 원하는 값을 찾아낼 수 있는 것인데 사용방법을 잘 몰라서 습관처럼 배열로 풀어내려고 기를 쓰다보니 제대로 된 답이 도출되지 않은 것 같다.
음. 오늘 나온 개념에 대해 조금 쉬운 문제를 풀어봐야겠다.
'Algorithm > Leetcode' 카테고리의 다른 글
| [leetcode] 200. 섬의 개수 (Number of Islands) (0) | 2022.05.20 |
|---|---|
| [leetcode] 706. 해시맵 디자인 (Design HashMap) (0) | 2022.05.19 |
| [leetcode] 29. 보석과 돌 (Jewels-and-stones) (0) | 2022.05.18 |
| [leetcode] 25. 원형 큐 디자인 (Design Circular Queue) (0) | 2022.05.17 |
| [leetcode] 739. 일일 온도 (Daily Temperatures) (0) | 2022.05.17 |